Cloudflare 作为领先的内容分发网络 (CDN) 服务提供商、网络安全和 DDoS 缓解专家,在 2025 年 12 月 5 日经历了一次显著的宕机事件。该事件的详细信息在其官方事后分析博客文章中公布,此次事件扰乱了其大量用户群的服务。
事件概述
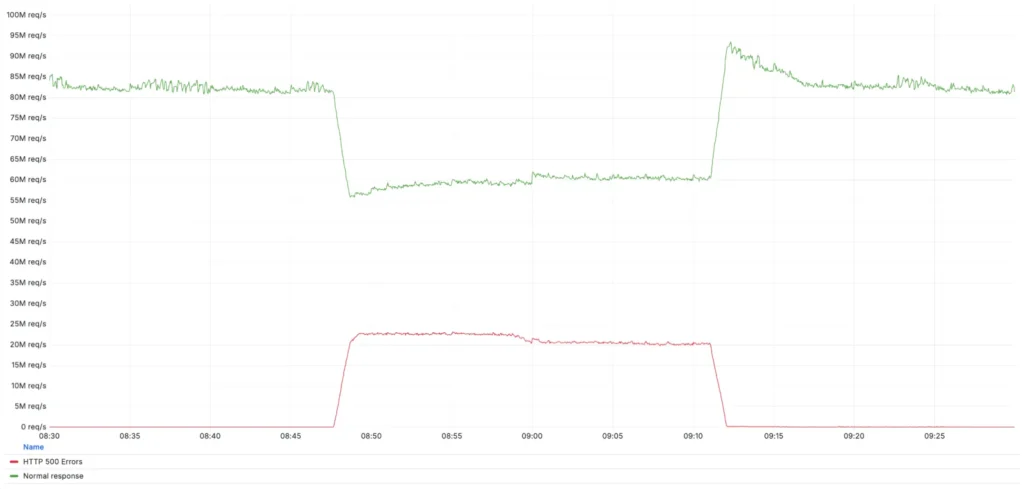
宕机于 2025 年 12 月 5 日 UTC 时间 08:47 开始,并于 09:12 解决,持续约 25 分钟。在此期间,受影响的用户遇到 HTTP 500 错误,这是服务器端问题,表示请求无法处理。重要的是,此次事件并非网络攻击或外部威胁所致,而是源于针对漏洞的内部配置更改。 该事件影响了 Cloudflare 总 HTTP 流量的约 28%,针对使用特定配置的客户子集。
此次事件紧随 2025 年 11 月 18 日的类似宕机之后,表明 Cloudflare 的部署流程可能存在系统性问题。虽然持续时间较短,但 Cloudflare 网络的全球规模放大了其影响,突显了互联数字基础设施的脆弱性。
事件时间线
图片来自于Cloudflare
理解事件序列对于分析问题如何快速升级和被控制至关重要。以下是逐步分解:
- 08:47 UTC:配置更改被部署并开始在 Cloudflare 的全球网络中传播。这标志着事件的开始。
- 08:48 UTC:更改完全传播,导致峰值影响,广泛出现 HTTP 500 错误。
- 08:50 UTC:自动警报触发,Cloudflare 宣布事件,调动响应团队。
- 09:11 UTC:团队识别问题并启动配置更改的回滚。
- 09:12 UTC:回滚完全传播,恢复网络正常服务。
这一快速时间线突显了 Cloudflare 的监控能力,但也揭示了即时全球部署如何将小问题转化为广泛中断。
根源原因分析
宕机的核心是两个相互关联的更改,旨在增强安全性:
- 缓冲区大小增加:Cloudflare 将 Web 应用防火墙 (WAF) 缓冲区大小从 128KB 增加到 1MB。这是针对 CVE-2025-55182 的主动措施,该漏洞是 React Server Components 中的行业性问题。 rollout 是渐进的,最小化了初始风险。
- 禁用内部测试工具:一个与新缓冲区大小不兼容的内部 WAF 测试工具被禁用,使用 Cloudflare 的全球配置系统。与缓冲区更改不同,此禁用即时传播,没有分阶段 rollout。
这种组合在较旧的 FL1 代理软件中触发了 Lua 异常:“attempt to index field ‘execute’ (a nil value)”。这发生在代码期望在通过 killswitch 跳过行为异常规则后有一个有效的 ‘execute’ 对象,但在此条件下它为 nil。该 bug 特定于使用 FL1 代理并启用 Cloudflare 托管规则集的客户。 值得注意的是,较新的 FL2 代理(用 Rust 编写)没有表现出此缺陷,Cloudflare 中国网络中的服务或那些没有受影响规则集的服务保持运行。
这一分析指出了经典软件工程陷阱:遗留代码中未经测试的边缘案例,被快速、非渐进部署放大。即时的 killswitch 更改传播充当了“爆炸半径”放大器,将局部问题转化为全球问题。
影响评估
宕机的效果是有针对性的但重大的:
- 受影响服务:主要影响使用 FL1 代理和托管规则集的客户网站 HTTP 请求,导致全面 HTTP 500 错误(少数例外如 /cdn-cgi/trace)。
- 范围:约 28% 的 Cloudflare HTTP 流量受影响,转化为数千网站潜在 downtime,包括电子商务平台、媒体出口和企业应用。
- 未受影响区域:通过中国网络路由的流量或不匹配配置继续不受中断。
对于企业而言,即使 25 分钟的宕机也可能导致收入损失、用户不满和声誉损害。在期望 uptime 接近 100% 的世界中,此事件很可能促使受影响客户审查 SLA(服务水平协议)并制定应急计划。
响应与缓解
Cloudflare 的响应迅速,遵守其标准操作程序 (SOP)。到 09:11 UTC,他们使用相同的 killswitch 系统回滚配置,在一分钟内完全解决问题。团队在其博客文章中发布了公开道歉,承认在 11 月事件后的复发,并承诺透明度。
这种高效缓解展示了强大的事件响应协议,包括自动警报和快速回滚机制。然而,它也引发了为什么类似问题如此紧密复发的问题——表明事后跟进存在差距。
经验教训与预防措施
Cloudflare 的事后分析详尽可嘉,概述了几个教训和计划改进:
- 部署增强:为配置引入健康验证、快速回滚和爆炸半径缓解,类似于其软件部署实践。
- 错误处理改进:在关键组件中转向“fail-open”逻辑,其中错误被记录但流量以安全默认状态继续。
- Break Glass 能力:简化紧急操作以确保故障期间的功能。
- 网络锁定:停止所有网络更改,直到实施更好的系统。
他们计划下周发布详细的弹性项目分解,强调安全相关更新的 containment。 从分析师的角度来看,这些步骤符合站点可靠性工程 (SRE) 的最佳实践,如 Google 的 playbook。然而,对遗留 FL1 代码的依赖表明需要加速迁移到现代替代品如 FL2。
更广泛的行业启示包括快速安全补丁与稳定性之间的权衡。像 CVE-2025-55182 这样的漏洞迫使快速行动,但没有稳健测试,它们可能适得其反。
结论
2025 年 12 月 5 日的 Cloudflare 宕机事件提醒我们管理全球规模基础设施的复杂性。虽然事件被快速控制,但其根源在于配置失误和遗留 bug,突显了改进领域。Cloudflare 的透明报告是积极的一步,促进信任并使社区集体学习。
对于使用 Cloudflare 或类似服务的组织,此事件强调了多元化架构、实时监控和稳健 failover 策略的重要性。随着我们前进,我将关注他们弹性举措的更新——希望将这些挫折转化为未来的更强保障。
图片和数据内容来自于 https://blog.cloudflare.com/5-december-2025-outage